- Hierarchies
- Restricted & calculated measures
- Input Parameters
- Currency conversion
- Filter operations and variables
HIERARCHIES: Hierarchies are used to structure and define the relationships among attributes of attribute views used for business analysis.HANA supports two types of hierarchy.
- Level Hierarchies are hierarchies that are rigid in nature, where the root and the child nodes can be accessed only in the defined order. For example, organizational structures, and so on.
- Parent/Child Hierarchies are value hierarchies, that is,hierarchies derived from the value of a node. For example, a Bill of Materials(BOM) contains Assembly and Part hierarchies, and an Employee Master record contains Employee and Manager data. The hierarchy can be explored based on a selected parent; there are also cases where the child can be a parent.
This discussion will helps us to create a Level Hierarchy or a Parent Child Hierarchy in order to structure and define relationship between view attributes.
- In the Hierarchy Type dropdown, select the required option as follows:
- Level Hierarchy
- Parent Child Hierarchy
- In the Node tab page, perform the following based on your selection of hierarchy type:
- For a Level Hierarchy you can specify the Node Style that determines the unique node ID composition. Also, add various levels and assign attributes to each of them with the Level Type that specifies the formatting instructions for the level attributes. Specify Order By to control the hierarchy members ordering, and Sort Direction to sort the hierarchy members display in ascending or descending order.
- For a Parent Child Hierarchy specify the parent and the child attribute. Also, in the Step Parent node specify where to place the orphan parent-child pair.
- In the Advanced tab page, specify the other properties of the hierarchy which are common to both hierarchy types as follows:
You can set Aggregate All Nodes to true if there is a value posted on the aggregate node and you want to compute that value while aggregating data.
- Specify the default member
- You can select Add a Root Node if you want to create a root node if the hierarchy does not have any
- Specify how to handle orphan nodes using Orphan Nodes dropdown
- Select Multiple Parent if the hierarchy needs to support multiple parents for its members
LEVEL HIERARCHIES:
- Select the Semantics node.
- In the Hierarchies panel, choose Create option.
- Enter a name and description for the hierarchy.
- In the Hierarchy Type dropdown, select Level Hierarchy.
- In the Node tab page do the following:
- Select the required value from the Node Style dropdown list. Note Node style determines the composition of a unique node ID. The different values for node styles are as:
- Level Name - the unique node ID is composed of level name and node name, for example "[Level 2].[B2]".
- Name Only - the unique node ID is composed of level name, for example "B2".
- Name Path - the unique node ID is composed of the result node name and the names of all ancestors apart from the (single physical) root node. For example "[A1].[B2]".
- Add the required columns as levels from the drop-down list. Note You can select columns from the required table fields in the drop-down list to add to the view.
- Select the required Level Type. Note The level type is used to specify formatting instructions for the level attributes. For example, a level of the type LEVEL_TYPE_TIME_MONTHS can indicate that the attributes of the level should have a text format such as "January", and LEVEL_TYPE_REGULAR indicates that a level does not require any special formatting.
- To control how the memebers of the hierarchy are ordered, select the required column in the OrderBy drop-down list. Note In the MDX client tools, the members will be sorted on this attribute.
- To sort the display of the hierarchy members in the ascending or descending order, select the required option from the Sort Direction drop-down list.
- In the Advanced tab page do the following:
- Select the required value in the Aggregate All Nodes. Note This option indicates that data is posted on aggregate nodes and should be shown in the user interface. For example, if you have the members A with value 100, A1 with value 10, and A2 with value 20 where A1 and A2 are children of A. By default the value is set to false, and you will see a value of 30 for A. With the value set to true, you will count the posted value 100 for A as well and see a result of 130. If you are sure that there is no data posted on aggregate nodes you should set the option to false. The engine will then calculate the hierarchy faster as when the option is set. Note that this flag is only interpreted by the SAP HANA MDX engine. In the BW OLAP engine the node values are always counted.
- Enter a value for the default member.
- To specify how to handle the orphan nodes in the hierarchy, select the required option as described below from the dropdown.
| Option | Description |
|---|
| Root Node | Treat them as root nodes |
| Error | Stop processing and show an error |
| Ignore | Ignore them |
| Step Parent | Put them under a step-parent node Note This enables you to create a text node and place all the orphaned nodes under this node. |
- Optional Step: If you have selected Step Parent in the Orphan Nodes drop-down, enter a value to create the step-parent node.
- Select the Add a Root Node check-box if required. Note If a hierarchy does not have a root node but needs one for reporting use case, select this option. This will create a root node with the technical name “ALL” .
- If the level hierarchy needs to support multiple parents for its elements for example, Country 'Turkey' to be assigned to two regions 'Europe' and 'Asia', select the Multiple Parent check-box.
- Choose OK.
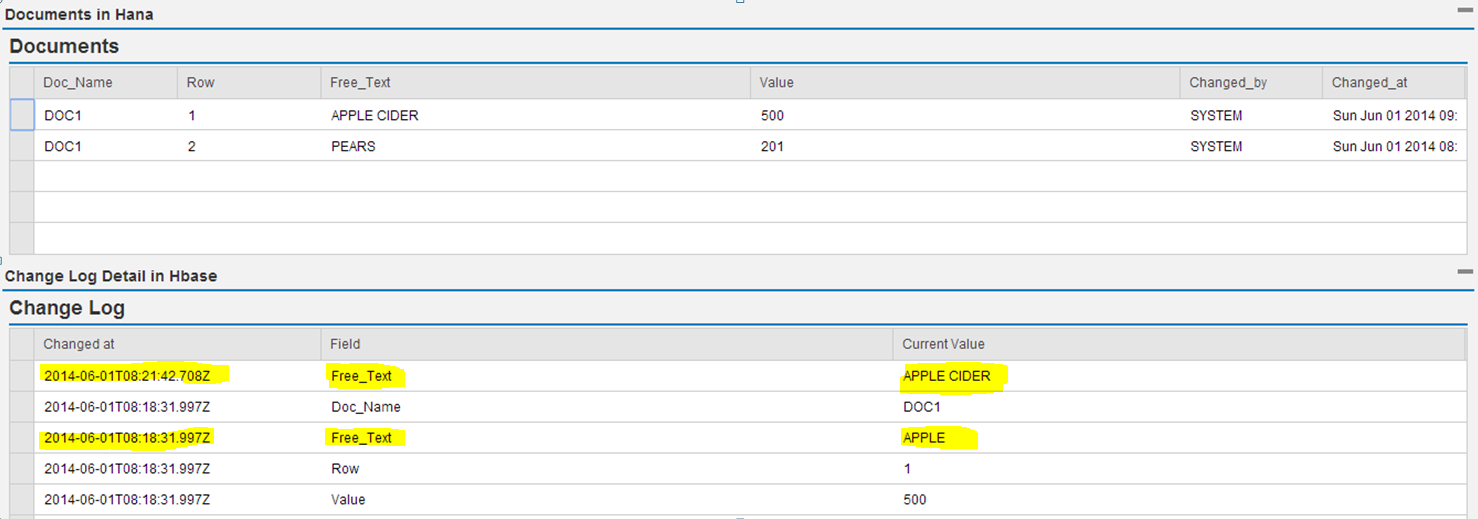
Let us take a scenario to explain Level Hierarchies. In eFashion package we created an Attribute View for Article_Lookup table below is the table fields
- ARTICLE_ID
- ARTICLE_LABEL
- CATEGORY
- SALE_PRICE
- FAMILY_NAME
- FAMILY_CODE
Here we can define a hierarchy by using field CATEGORY & ARTICLE_LABEL.
- Open AV_AL (Attribute View-Article_Lookup)
- Select Semantics.
- Click on PLUS icon on Hierarchy box.
- Provide Hierarchy definition(Name, Type, Node)
- In Hierarchy Type –select Level Hierarchy.
- OK,Validate & Save and Activate.
- Activate Analytic View wherein AV_AL consumed.
![AV_HR.jpg]()
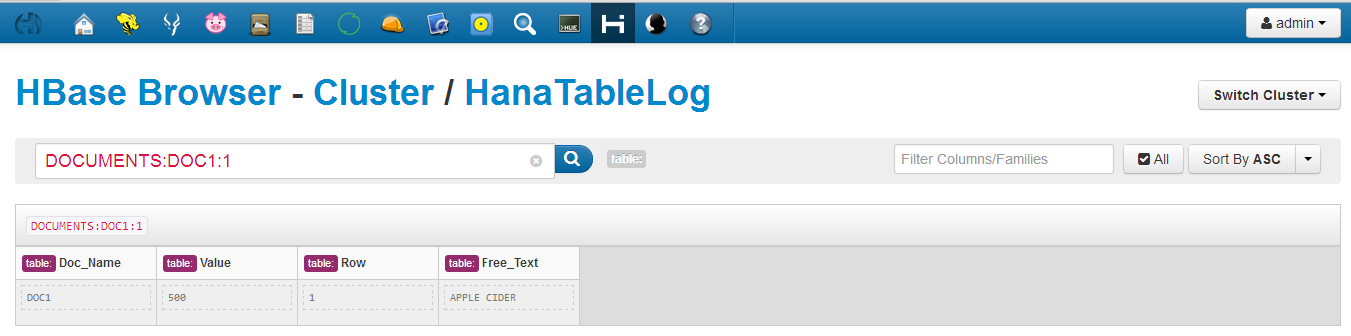
![AV_HR1.jpg]() CONSUMED HEIRARCHY USING MDX PROVIDER:
CONSUMED HEIRARCHY USING MDX PROVIDER:
- Open Excel workbook > Data > From Other
Sources > Select “From Data Connection Wizard” - Select Other/Advanced from Data ConnectionWizard.
- Select “SAP HANA MDX PROVIDER”, NEXT
- Provide SAP HANA login credential, OK.
- Select Package and cube (AV_SHOP_FACT), NEXT
![AV_HR2.jpg]()
PARENT/CHILD HIERARCHY:
- Select the Semantics node.
- In the Hierarchies panel, choose Create option .
- Enter a name and description for the hierarchy.
- In the Hierarchy Type dropdown, choose Parent Child Hierarchy.
- In the Node tab page, add the parent and child nodes by selecting the Parent Node and Child Node from the drop-down list. Note In case you decide to place the orphaned parent-child pair under a node called Step Parent from the Advanced tab page, you can specify its value in the Step Parent column. The step-parent node could only be one of the column or calculated column or the current view. You can specify different step-parent values for all the parent-child pairs. These values appear as a comma separated list in the Advance tab page Step Parent field. In case of a single parent-child node, you can also specify the value for step-parent node in the Advanced tab page. The same value appears in the Node tab page.
- In the Advanced tab page, do the following: Choose OK.
- Select the required value in the Aggregate All Nodes. Note This option indicates that data is posted on aggregate nodes and should be shown in the user interface. For example, if you have the members A with value 100, A1 with value 10, and A2 with value 20 where A1 and A2 are children of A. By default the value is set to false, and you will see a value of 30 for A. With the value set to true, you will count the posted value 100 for A as well and see a result of 130. If you are sure that there is no data posted on aggregate nodes you should set the option to false. The engine will then calculate the hierarchy faster as when the option is set. Note that this flag is only interpreted by the SAP HANA MDX engine. In the BW OLAP engine the node values are always counted.
- Enter a value for the default member.
- To specify how to handle the orphan nodes in the hierarchy, select the required option as described below from the dropdown.
| Option | Description |
|---|
| Root Node | Treat them as root nodes |
| Error | Stop processing and show an error |
| Ignore | Ignore them |
| Step Parent | Put them under a step-parent node Note This enables you to create a text node and place all the orphaned nodes under this node. |
- Optional Step: If you have selected Step Parent in the Orphan Nodes dropdown, enter a value to create the step-parent node.
- Select the Add Root Node checkbox if required as described below. Note If a hierarchy does not have a root node but needs one for reporting use case, set the option to true. This will create a root node.
- If the level hierarchy needs to support mulitple parents for its elements for example, Country 'Turkey' to be assigned to two regions 'Europe' and 'Asia', select the Mulitple Parent checkbox.
Note: The hierarchies belonging to an attribute view are available in an analytic view that reuses the attribute view, in read-only mode. However, the hierarchies belonging to an attribute view are not available in a calculation view that reuses the attribute view.
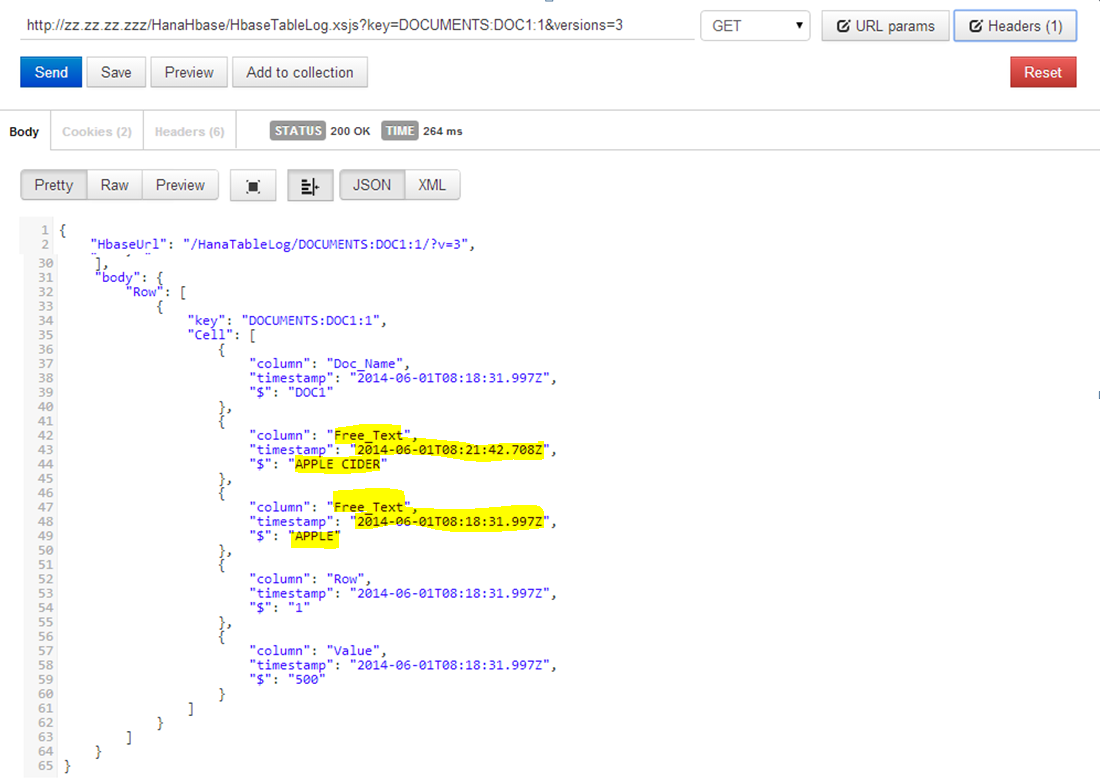
Let us take a scenario of Parent –Child relationship in ITEM_MASTER table. Here for Item ID 2 and 3 the parent ID is 1 i.e. to say item id 2 & 3 falls under CONSUMABLES. Similarly Item 5 to 8 fall under STEEL category. Parent/Child Hierarchy type can be used to define Hierarchy in this scenario.
| ITEM_ID | PARENT_ITEM_ID | ITEM_DESCRIPTION |
|---|
| 1 | | CONSUMABLES |
| 2 | 1 | Cutting Disc 4” |
| 3 | 1 | Grinding Disc 4” |
| 4 | | STEEL |
| 5 | 4 | Plate 10mm |
| 6 | 4 | Beam |
| 7 | 4 | Angle |
| 8 | 4 | Channel |
![AV_HR4.jpg]()
RESTRICTED COLUMN:
Restricted Columns are used to filter the value based on the user defined rules on the attribute values.
Restricted Column dialog helps to create a restricted column and filter its value based on the columns that you select in the Restrictions view. In the Column dropdown, you can select a column of type measure for which you want to apply filter. In the Restrictions view, to apply a filter, you need to choose Add Restriction. Select a Column, an Operator, and enter a value. For example, you can create a restricted column to view the Revenue of a particular country, where Revenue is the measure and Country is the attribute having a list of countries. If you have added many restrictions, and do not want to apply all of them but want to retain them, deselect the Include checkbox.
Creating a Restricted Column
You use this procedure to create a restricted column to filter the value based on the user-defined restrictions for the attribute values.
For example, to filter the sales of a product based on a category you can create a restricted column Sales based on a measure Total Sales amount, and attribute category where you can restrict the value for category.
1. In the Output panel of the Logical Join, right-click Restricted Columns, and choose New.
2. Enter a name and description for the restricted column.
3. From the Column dropdown, select a measure.
4. In the Restrictions view, choose Add Restriction.
1. In the Column dropdown, select column to define filter.
2. Select the required operator.
3. Enter the filter value.
4. If you want to remove a particular filter on the column, deselect its corresponding Include checkbox.
5. Choose OK.
![REST_COL.jpg]()
Data preview shows Sales amount for only restricted attributes i.e, category "Jewelry" & Category "Pants".
![REST_COL1.jpg]()
Lets review below senario where in "Jewelry" category has been excluded.
![REST_COL2.jpg]()
Here you can see sales amount of all category except category "Jewelry".
![REST_COL3.jpg]()
CALCULATED COLUMN:Calculated columns are used to derive some meaningful information in the form of columns, from existing columns.
Calculated Column dialog helps you to derive a calculated column of type attribute or measure based on the existing columns, calculated columns,restricted columns, and input. You can write the formula in the Expression panel or assemble it making use of the available Elements, Operators and Functions.
You can specify how to aggregate row data for calculated column of type measure using the Calculate Before Aggregation checkbox and specifying Aggregation Type. If you select the Calculate Before Aggregation,the calculation happens as per the expression specified and then the results are aggregated as SUM, MIN, MAX or COUNT. If Calculate Before Aggregation is not selected, the data is not aggregated but it gets calculated as per calculation expression (formula), and the Aggregation is shown as FORMULA. After writing the expression, you can validate it using Validate.
You can also associate a calculated column with Currency or Unit of Measure using the Advanced tab page.
CREATING CALCULATED COLUMN
You use calculated columns to derive some meaningful information, in the form of columns, from existing columns, calculated columns, restricted columns and input parameters.
For example:
- To derive postal address based on the existing attributes.
- To prefix the customer contact number with the country code based on the input parameter country.
- To write formula in order to derive values like,
if("PRODUCT" = 'ABC, "DISCOUNT" * 0.10,
"DISCOUNT") if attribute PRODUCT equals the string ‘ABC’ then DISCOUNT
equals to DISCOUNT multiplied by 0.10 should be returned. Otherwise the
original value of attribute DISCOUNT should be used.
Procedure
1. In the Output panel of the Logical Join,right-click Calculated Columns, and choose New.
2. Enter a name and description for the calculated column.
3. Select the data type, and enter length and scale for the calculated column.
4. Select the Column Type to specify the calculated column as attribute or measure.
5. In case of measure column type, if you select Calculate Before Aggregation, select the aggregation type.
Note: If you select Calculate Before Aggregation, the calculation happens as per the expression specified and then the results are aggregated as SUM, MIN, MAX or COUNT. If Calculate Before Aggregation is not selected, the data is not aggregated but it gets calculated as per calculation expression (formula), and the Aggregation is shown as FORMULA.If the aggregatoin is not set, then it will be considered as attribute.
6. In the expression editor enter the expression or assemble it using the menus in the below window.
7. If you want to associate the calculated column with currency and unit of measuring quantity, select the Advanced tab page and select the required type.
8. Choose OK.
![calculated_column.png]()
INPUT PARAMETER:
You use this procedure to allow you to provide input for the parameters within stored procedures, to obtain a desired functionality when the procedure is executed.
In an Analytic View you use input parameters as placeholders during currency conversion, formulas like calculated columns where the calculation of the formula is based on the input you provide at runtime during data preview. Input parameters are not used for filtering attribute data in Analytic View that is achieved using variables.
In calculation Views you can use input parameter to during currency conversion, calculated measures, input parameters of the script node and to filter data as well.
You can apply input parameters in analytic and calculation views. If a calculation view is created using an analytic view with input parameters, those input parameters are also available in the calculation view but you cannot edit them.
The following types of input parameters are supported:
Type |
Description |
Attribute Value/
Column |
Use this when the value
of a parameter comes from an attribute. |
Currency (available
in Calculation View only) |
Use this when the
value of a parameter is in a currency format, for example, to specify the
target currency during currency conversion. |
Date (available in Calculation
View only) |
Use this when the
value of a parameter is in a date format, for example, to specify the date
during currency conversion. |
Static List |
Use this when the
value of a parameter comes from a user-defined list of values. |
Derived From Table
(available in Analytic View and Graphical Calculation View) |
Use this when the
value of a parameter comes from a table column based on some filter
conditions and you need not provide any input at runtime. |
Empty |
Use this when the
value of a parameter could be anything of the selected data type. |
Direct Type
(avaliable in Analytic View) |
To specify an input
parameter as currency and date during currency conversion. |
|
Each type of input parameter can be either mandatory or non-mandatory. For a mandatory input parameter, it is necessary to provide a value at runtime. However, for a non-mandatory input parameter, if you have not specified a value at runtime,the data for the column where the input parameter is used remains blank.
Note:You can check whether an input parameter is mandatory or not from the properties of the input parameter in the properties pane.
- If you want to create a formula to analyze the annual sales of a product in various regions, you can use Year and Region as input parameters.
- If you want to preview a sales report with data for various countries in their respective currency for a particular date for correct currency conversion, you can use Currency and Date as input parameters.
Procedure
In Analytic View
- In the Output panel of the Data Foundation or Logical Join node, right-click the Input Parameters node.
- Note: You can also create input parameters at the Semantics node level, using the Create Input Parameter option in the Variables/Input Parameters panel.
- From the context menu, choose New.
- Enter a name and description.
- Select the type of input parameter from the Parameter Type drop-down list.
- For the Column type of input parameter, you need to select the attribute from the drop-down list. At runtime the value for the input parameter is fetched from the selected attribute's data.
- For input parameter of type Derived from Table, you need to select a table and one of it's column as Return Column whose value is used as input for formula caluclation. You can also define conditions to filter the values of Return Column in the Filters panel. For example, to calculate Discount for specific clients, you can create an input parameter based on Sales table and return column Revenue with filter set on the Client_ID.
- For Direct Type input parameter, specify the Semantic Type that describes the use parameter as a currency or date , for example, to specify the target currency during currency conversion.
- If required, select a data type.
- Enter length and scale for the input parameter.
- Choose OK.
In Calculation View
- In the Output panel,right-click the Input Parameters node.
- From the context menu, choose New.
- Enter a name and description.
- Select the type of input parameter from the drop-down list.
- For the Attribute Value type of input parameter, you need to select the attribute from the drop-down list. At runtime the value for the input parameter is fetched from the selected attribute's data.
- For input parameter of type Derived from Table, you need to select a table and one of it's column as Return Column whose value is used as input for formula caluclation. You can also define conditions to filter the values of Return Column in the Filters panel. For example, to calculate Discount for specific clients, you can create an input parameter based on Sales table and return column Revenue with filter set on the Client_ID.
- Select a data type.
- Enter length and scale for the input parameter.
- Choose OK.
CURRENCY & UNIT OF MEASURE:
Measures used in analytic views and calculation views can be defined as amount or weight in the analytical space using currency and unit ofmeasure. You can also perform currency conversion and unit of measure conversion.
For example, you need to generate a sales report for a region in a particular currency, and you have sales data in database tables ina different currency. You can create an analytic view by selecting the table column containing the sales data in this other currency as a measure, and perform currency conversion. Once you activate the view, you can use it to generate reports.
Similarly, if you need to convert the unit of a measure from cubic meters to barrels to perform some volume calculation and generate reports, you can convert quantity with unit of measure.
To simplify the process of conversion, system provides the following:
- For currency conversion - a list of currencies, and exchange rates based on the tables imported for currency
- For quantity unit conversion - a list of quantity units and conversion factors based on the tables imported for units.
Currency conversion is performed based on the source currency, target currency, exchange rate, and date of conversion. You can also select currency from the attribute data used in the view.
Similarly, quantity unit conversion is performed based on the source unit,target unit, and conversion factor.
You can also select the target currency or unit of measure at query runtime using input parameters. If you use this approach then, you have to first create an input parameter with the desired currency/unit specified, and use the same input parameter as target in the conversion dialog.
Note
Currency conversion is enabled for analytic views and base measures of calculation views.
Prerequisites
You have imported tables T006, T006D, and T006A for Unit of Measure.
You have imported TCURC, TCURF, TCURN, TCURR, TCURT, TCURV, TCURW, and TCURX for currency.
Procedure
- Select a measure.
- In the Properties pane, select Measure Type.
- If you want to associate the measure with a currency, perform the following substeps:
a. In the Measure Type dropdown list, select the value Amount with Currency.
b.In the Currency Dialog,select the required Type as follows:
Type |
Purpose |
|---|
Fixed |
To select currency from the currency table TCURC. |
Attribute |
To select currency from one of the attributes used in the view. |
c. Select the required value, and choose OK.
d. If you want to convert the value to another currency, choose Enable for Conversion.
i.To select the source currency, choose Currency.
ii..Select the target currency.
Note: For currency conversion, in addition to the types Fixed and Attribute, you can select Input Parameter to provide target currency at runtime. If you select an input parameter for specifying target currency and deselect Enable for Conversion checkbox, the target currency field gets clear because input parameters can be used only for currency conversion.
iii.To specify exchange rate type, in the Exchange Rate Types dialog, select the Type as follows:
Type |
Purpose |
Fixed |
To select exchange rate from the currency table TCURW. |
Input Parameter |
To provide exchange rate input at runtime as input parameter. |
iv.To specify the date for currency conversion, in the Conversion Date dialog, select the Type as follows:
Type |
Purpose |
Fixed |
To select conversion date from the calendar. |
Attribute |
To select conversion date from one of the attributes used in the view. |
Input Parameter |
To provide conversion date input at runtime as input parameter. |
v.To specify the schema where currency tables are located for conversion, in the Schema for currency conversion, select the required schema.
vi.To specify the client for which the conversion rates to be looked for, in the Client for currency conversion, select the required option.
e. From the dropdown list, select the required value that is used populate data if the conversion fails:
Option |
Result |
Fail |
In data preview, the system displays an error for conversion failure. |
Set to NULL |
In data preview, the value for the corresponding records is set to NULL. |
Ignore |
In data preview, you view the unconverted value for the corresponding records. |
4.If you want to associate a measure with a unit of measure other than currency, perform the following substeps:
a. Select the value Quantity with Unit of Measure in the Measure Type drop-down list.
b. In the Quantity Units dialog, select the required Type as follows:
Type |
Purpose |
Fixed |
To select a unit of measure from the unit tables T006 and T006A. |
Attribute |
To select a unit of measure from one of the attributes used in the view. |
c. Select the required value, and choose OK.
5.Choose OK.
Note You can associate Currency or Unit of Measure with a calculated measure, and perform currency conversion for a calculated measure by editing it
![Currency_Con_Fixed.png]()